Egy rövid project (twitter sentiment analysis with vaderSentiment method) keretein belül az rPython csomagot használtuk és az ezzel kapcsolatos tapasztalatot szeretnénk most megosztani.
A project során tweet-ket gyűjtöttünk és egy adattáblába szerveztük őket. Ezután a python nyelven megírt VaderSentiment módszerrel elemeztük a tweeteket. A módszer lényege, hogy egy adott szöveget a benne lévő szavak, hangulatjelek és egyéb más rövidítések (pl.: LOL stb.) alapján számít ki 4 értéket (negatív, neutrális, pozitív és összesített).
Egy példa, a kapcsos zárójelben a számított értékek:
“VADER is smart, handsome, and funny.”
{‘neg’: 0.0, ‘neu’: 0.254, ‘pos’: 0.746, ‘compound’: 0.8316}
Értékelés:
A mondatban nem volt negatív töltésű rész. Körülbelül a szöveg ~25%-a semleges, míg a maradék ~75% pozitív kincsengésű volt. Összességében a normalizált “compound” érték 0.83 volt (-1 és 1 között lehet). Ha > 0.05, akkor pozitív, ha < -0.05, akkor negatív töltöttségű a szöveg. Ha ez az érték -0.05 és 0.05 között van, akkor semlegesnek tekinthető. Bővebb leírás itt.
50 darab tweet a #ecology tag-re keresve….adat
01 # rPython csomag betöltése02 03 04 # a tweet-ek behívása05 06 07 # a tweet-ek tisztítása: #,@ jelek törlése a szövegekből.08 09 10 11 12 13 # a változó átalakítása, hogy a python scriptbe tudjuk ágyazni14 # idézőjeleket teszünk a tweet-ek elejére és végére15 16 # vessző hozzáfűzése minden tweet végéhez az idézőjel után,17 # kivéve az utolsó sornál18 19 20 # python fájl kiírása egy fájlba21 # a számított értékeket először a "bs" változóba tároljuk, majd22 # a "mylist" listába gyűjtjük össze az összeset és ezt adjuk át az R-nek23 24 25 26 27 28 29 30 31 32 33 34 # python kód betöltése és futtatása35 36 # az eredmények átemelése R-be37 38 # az adatok adattáblába rendezése39 40 41 # az összesített eredmények egyszerű ábrázolása42 43 44 45 46 47
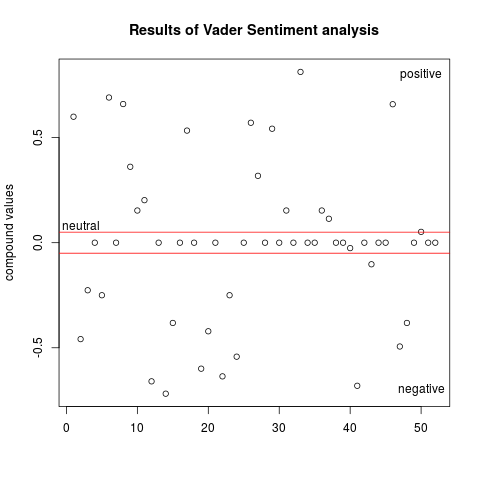
Az R és a python együttes használatával egy olyan eszköztárat kapunk, amivel gyakorlatilag bármilyen problémát meg lehet oldani! 🙂